Moderní vědní obor bioinformatika dnes slouží nejen při luštění genomu či modelování neznámých molekul pro vývoj nových léků, ale také například v kriminalistice, kde se s jeho pomocí dá třeba usvědčit pachatel trestného činu.
V 90. letech minulého století dostalo zelenou nové vědní odvětví zvané bioinformatika, které využívá všech nejnovějších znalostí v oboru biologie, stále výkonnějších počítačů a v neposlední řadě i všudypřítomného internetu. Možnosti využití bioinformatického výzkumu jsou nedozírné.
Bez počítače by to nešlo
Počítače zasahují do stále více oborů lidské činnosti. Nejinak je tomu tedy i v biologii, kde vědci zkombinováním obrovské výpočetní síly počítačů a vědomostí z „klasické“ biologie hledají vzájemné souvislosti mezi různými organismy v celém evolučním vývoji. To by se bez schopností počítačů namohlo nikdy podařit.
Asi nejznámější z tohoto hlediska je snaha o rozluštění genetických informaci, které si v sobě každý živý tvor nese. Bioinformatika rovněž usiluje o možnost předpovídat funkce biologických molekul, které na základě dědičné informace vznikají.
Brzdy na míru
Vědecky atraktivní součástí bioinformatiky je počítačové modelování trojrozměrných struktur biologických molekul, které zatím nebyly získány experimentálně. K čemu je nám taková znalost jejich prostorové struktury? Farmaceutické koncerny například vyrábějí léky takzvaně „na míru“, což jsou relativně malé molekuly, které přesně, jako klín do ozubeného soukolí, zapadnou do velké biomolekuly a zablokují tak její činnost. Jedná-li se o nějaký důležitý enzym, bez něhož nemůže určitý druh bakterie přežít, pak se tato malá molekula stane specifickým antibiotikem a medicína postoupí zase o krůček dál. Bez znalosti tvaru velké molekuly ovšem vědci nemohou takový účinný lék navrhnout.
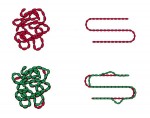
Jak se modeluje protein?
Řada prostorových struktur biomolekul (jedná se zejména o proteiny) již byla určena experimentálně, avšak takový postup je velice pracný a zdlouhavý. Je ovšem známo, že i příroda často používá osvědčené metody a že se tedy některé proteiny navzájem velmi podobají. Tak se ve vědeckých hlavách zrodila myšlenka, že by se dala prostorová struktura nějaké molekuly odvodit na základě analogie s jinou molekulou. Základním předpokladem je, aby obě srovnávané molekuly měly do jisté míry podobný sled aminokyselin, které je tvoří.
Protein si můžeme představit jako řetízek korálků (aminokyselin), zmuchlaný do klubka, avšak tento chuchvalec, i když se to na první pohled nezdá, má přesně danou architekturu. Vlastní modelování pak probíhá v podstatě tak, že oba řetízky natáhneme, přilepíme je k sobě v místech, kde si odpovídají, a pak je současně zmuchláme do původního tvaru „klubka“ – proteinu.
Po stopách pachatele
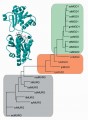
Další zajímavou kapitolou bioinformatiky je určování příbuzenských vztahů mezi různými organismy, které se vyvinuly během několika milionů let evoluce. Historické způsoby klasifikace rostlin a živočichů byly založeny na vzájemném srovnávání jejich anatomických znaků. První přírodovědci odvedli obrovský kus práce, ale v některých případech, jak později vyšlo najevo, se spletli,.
Dnes má věda k dispozici výkonné laboratorní přístroje zvané sekvenátory, které „přečtou“ genetickou informaci (často stačí i její část) prakticky kteréhokoli organismu. Používají se mj. v soudním lékařství při identifikaci obětí či pachatelů, kdy k dispozici není jiný důkaz než kousek tkáně.
Prvotním výstupem ze sekvenátorů je dlouhá řada písmen, která nezasvěcenému člověku připadne jako nerozluštitelná šifra. Ve světových databázích však existují obrovská množství písmenných sekvencí, které byly získány obdobným způsobem. A zde přicházejí na řadu supervýkonné počítače, jež srovnají nově nalezenou sekvenci s dříve určenými „šiframi“ a přisoudí jí nové místo ve světové databázi. Známe-li druh organismu, ze kterého byla tkáň získána, můžeme jeho „šifru“ porovnat se sekvencemi organismů, o nichž se domníváme, že jsou příbuzné a tuto domněnku pak potvrdit či vyvrátit.
Řada organismů dosud čeká na své objevení (zejména v deštných pralesích nebo na mořském dně) a bioinformatika bude výkonným nástrojem, který pomůže tyto zoologické či botanické „nováčky“ správně zařadit do již existujícího taxonomického systému.
Rozluštíme sami sebe?
Sekvenátory se dnes používají i k rozsáhlým projektům, jako je přečtení kompletní genetické informace (tzv. genomu) vybraného organismu. Je to zdlouhavá práce a přestože již některé organismy byly „přečteny“, výsledky ještě nejsou navenek zcela zřejmé. Nejvyšší metou bioinformatiky je totiž rozluštění genomu, tedy určení funkcí jednotlivých úseků DNA, která je nositelkou genetických informaci. Tento úkol je neobyčejně náročný, protože struktura DNA je vysoce komplikovaná a příroda ji „zašifrovala“ tak dobře, že ani po několika desetiletích výzkumů nedokáže současná věda spolehlivě určit funkce některých neznámých úseků DNA.
Proslulý projekt HUGO, jehož úkolem bylo přečtení kompletního lidského genomu, byl dokončen na začátku tohoto století. Nikdo však zatím nedokáže odhadnout, jak dlouho bude trvat, než plně porozumíme genetické informaci, kterou v sobě nosíme. Až se tak jednou stane, možná budeme svědky tolik diskutovaných genových manipulací, které by snad mohly zabránit propuknutí některých vážných chorob.
Internetový svět bioinformatiky
Bioinformatikou se zabývá řada výzkumných ústavů na celém světě:
· European Bioinformatics Institute (EBI): http://www.ebi.ac.uk/
· National Center for Biotechnology Information (NCBI): http://www.ncbi.nlm.nih.gov/
· Swiss Institute of Bioinformatics (SIB): http://www.isb-sib.ch/
Databáze biologických dat jsou většinou volně přístupné každému, kdo o ně projeví zájem. Informace jsou přehledně uspořádány a návštěvník internetových stránek zde najde i podrobná vysvětlení, pokud něčemu nerozumí.
· Entrez: http://www.ncbi.nlm.nih.gov/gquery/gquery.fcgi
· Universal Protein Resource (UniProt): http://www.expasy.uniprot.org/
· Protein Data Bank (PDB): http://www.rcsb.org/pdb/